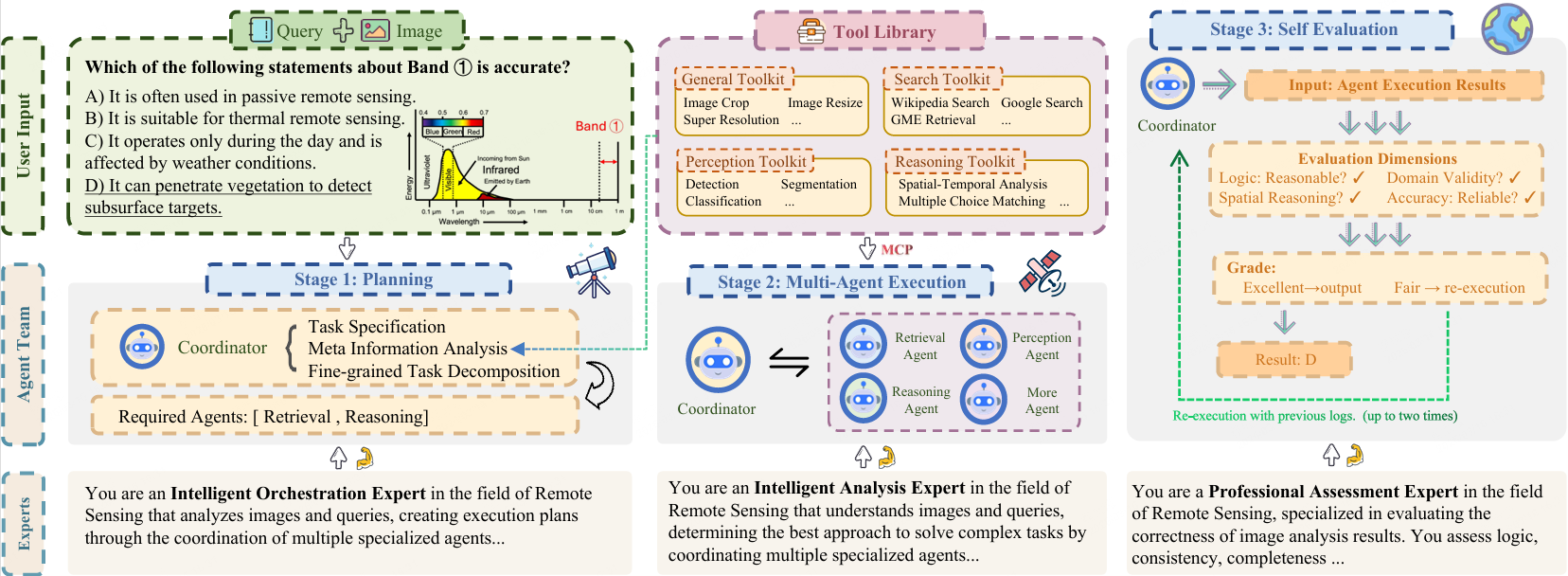
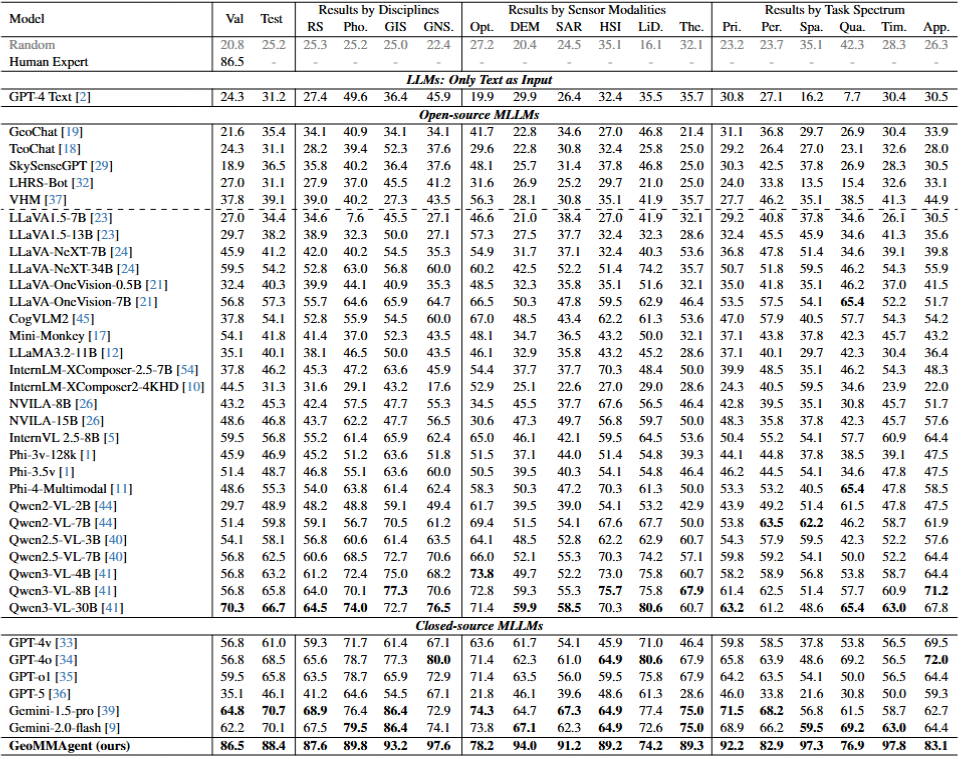
We present GeoMMBench, a comprehensive multimodal question-answering benchmark for geoscience and remote sensing, featuring 1,053 expert-level, image-based multiple-choice questions spanning four disciplines (Remote Sensing, Photogrammetry, GIS, GNSS), six sensor modalities (Optical, SAR, Hyperspectral, LiDAR, DEM, Thermal), and diverse tasks such as scene classification, object and change detection, spectral analysis, and spatial reasoning.
We further introduce GeoMMAgent, a multi-agent framework that follows a plan–execute–evaluate paradigm: a coordinator decomposes tasks; specialized agents handle general preprocessing, web and multimodal retrieval (including GME-based filtering), perception with YOLO11 and DeepLabV3+, and reasoning for option alignment. GeoMMBench evaluates 36+ vision-language models in zero-shot settings; GeoMMAgent achieves strong performance. The dataset is released on Hugging Face; code and configurations are publicly available.